딥러닝 그래서 어떻게 뭘 쓰는데? - LSTM을 활용한 기후 시계열 예측 (2)
안녕하세요. 여러분!
지난 포스팅에서는 딥러닝의 기본 개념과 MLP 기반 모델을 통해 기초 실습을 진행했습니다.
이번 포스팅에서는 이전에 다루지 않았던 순환 신경망(RNN) 및 LSTM(Long Short-Term Memory) 의 핵심 개념들을 새롭게 소개하고,
이를 기반으로 기후 시계열 데이터를 예측하는 심화 예제를 진행해 보겠습니다.
개념 소개: 순환 신경망과 LSTM
1. 순환 신경망 (RNN)의 기본 개념
- RNN의 필요성:
기존의 MLP나 CNN은 고정된 크기의 입력 데이터를 처리하는 데 강점을 보입니다.
하지만 시계열 데이터나 자연어와 같이 순서가 중요한 데이터의 경우,
이전 정보가 미래 예측에 중요한 역할을 하게 됩니다.
RNN(Recurrent Neural Network) 은 바로 이러한 순차적 데이터를 처리하기 위해 고안된 모델입니다. - RNN의 구조:
RNN은 입력 데이터를 시간 순서대로 처리하며,
각 시점에서 이전 시점의 출력을 현재 입력과 함께 다음 시점으로 전달합니다.
이로 인해 순환 구조(Recurrence) 를 가지며,
시간에 따른 패턴과 의존성을 모델링할 수 있습니다. - 한계:
RNN은 긴 시퀀스 데이터에서 기울기 소실(Vanishing Gradient) 또는 폭주(Exploding Gradient) 문제로 인해,
장기 의존성을 학습하는 데 어려움을 겪습니다.
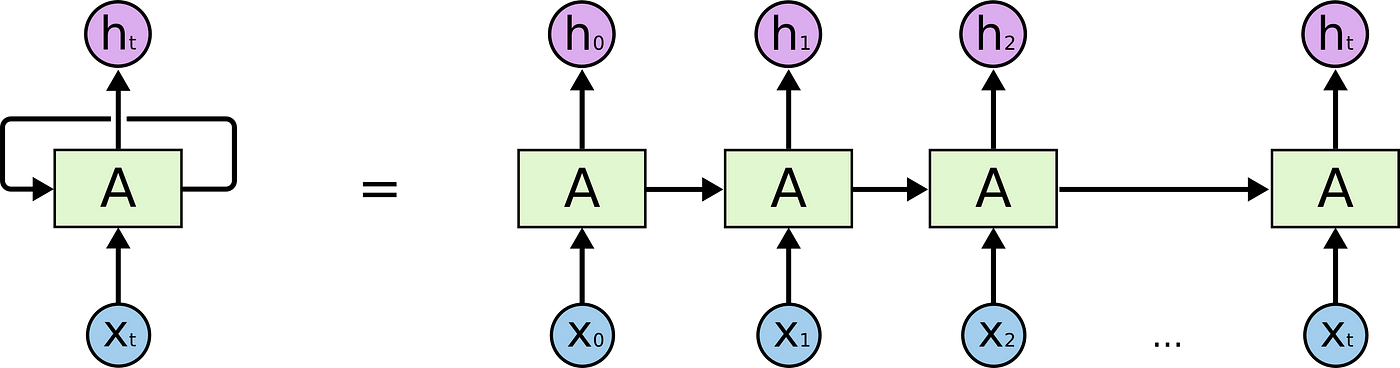
2. LSTM (Long Short-Term Memory)의 등장
- LSTM의 목적:
LSTM은 RNN의 단점을 보완하기 위해 개발되었습니다.
긴 시퀀스에서 중요한 정보를 장기간 보존하고,
불필요한 정보는 효과적으로 잊어버릴 수 있도록 설계되었습니다. - LSTM의 구성 요소:
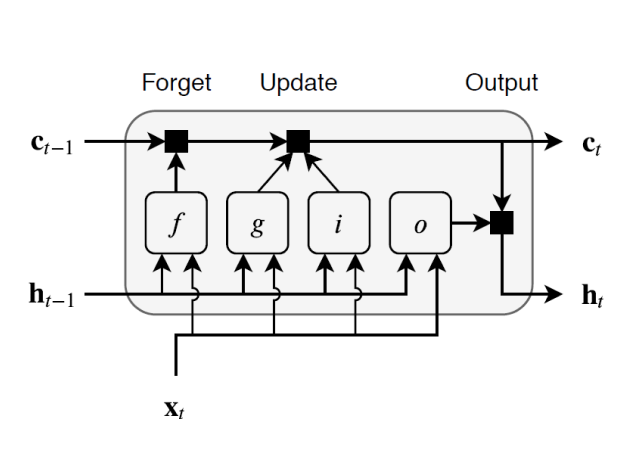
- 셀 상태(Cell State):
전체 시퀀스에 걸쳐 정보를 전달하는 경로로,
정보의 흐름을 그대로 유지하거나 약간 수정할 수 있습니다. - 게이트 메커니즘:
LSTM은 셀 상태에 정보를 추가하거나 제거하기 위해 여러 게이트를 사용합니다.- 입력 게이트(Input Gate): 새로운 정보를 얼마나 반영할지를 결정합니다.
- 망각 게이트(Forget Gate): 이전 셀 상태의 어떤 정보를 잊을지를 결정합니다.
- 출력 게이트(Output Gate): 최종적으로 출력할 정보를 결정합니다.
- 셀 상태(Cell State):
- 장점:
이와 같은 구조 덕분에 LSTM은 긴 시퀀스 데이터에서도 중요한 정보를 효과적으로 유지할 수 있어,
기후 데이터와 같이 장기 패턴을 갖는 시계열 분석에 적합합니다.
이처럼, RNN과 LSTM은 순차 데이터의 특성을 반영하여 이전 포스팅에서 다루지 않았던 새로운 접근법을 제시합니다.
이제 이 새로운 개념들을 바탕으로 LSTM을 활용한 기후 시계열 예측 예제를 진행해보겠습니다.
목차
- 1. 포스팅 개요
- 2. 새로운 개념 소개: RNN과 LSTM
- 3. 데이터 준비 및 전처리
- 4. LSTM 모델 구현
- 5. 모델 학습 및 평가
- 6. 결과 분석 및 활용 방안
- 7. 결론
1. 포스팅 개요
이번 포스팅에서는 새로운 순환 신경망 개념을 소개한 후,
LSTM을 활용해 10년간의 월별 평균 기온 데이터를 기반으로 다음 달 기온을 예측하는 예제를 진행합니다.
환경·기후 데이터 분석에 관심 있는 연구자 여러분께 실질적인 도움이 되기를 바랍니다.
2. 새로운 개념 소개: RNN과 LSTM
2.1. RNN의 기본 개념
- 순차 데이터 처리:
RNN은 입력 데이터를 순차적으로 처리하며,
각 시간 단계에서 이전 상태의 정보를 이용해 현재 출력을 생성합니다. - 순환 구조의 장점과 한계:
이를 통해 시간적 패턴을 학습할 수 있지만,
긴 시퀀스에서는 기울기 소실/폭주 문제가 발생하여 장기 의존성 학습에 한계가 있습니다.
2.2. LSTM의 구성 요소
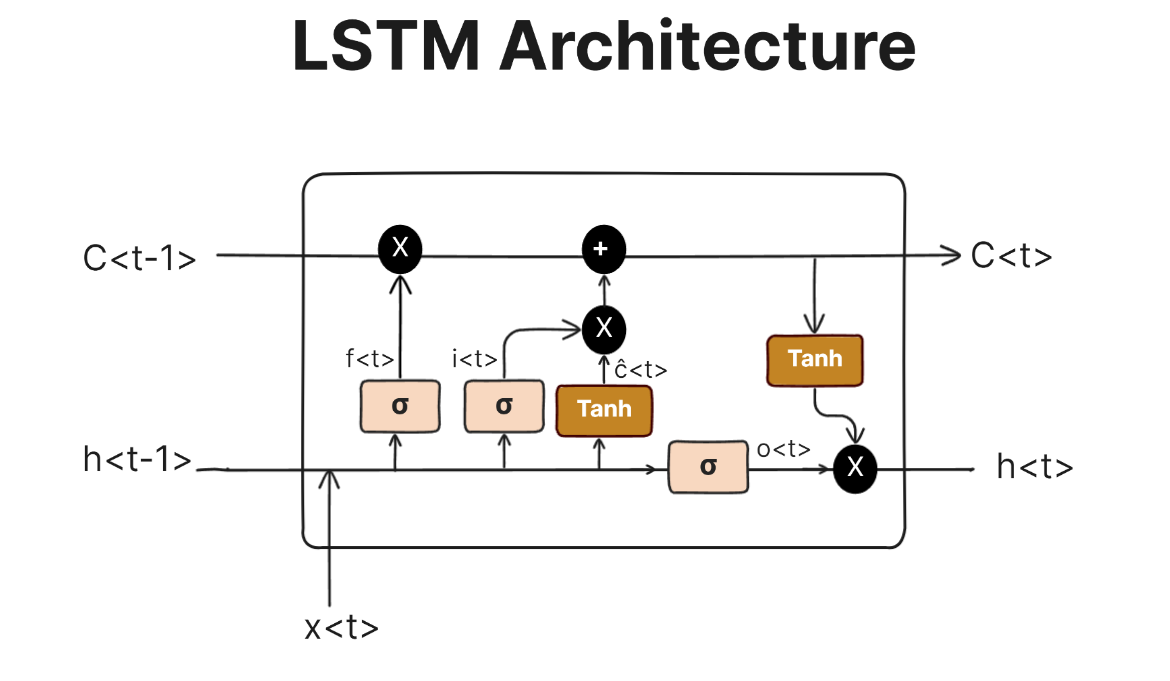
- 셀 상태(Cell State):
LSTM은 정보의 장기 전달을 위해 셀 상태라는 개념을 도입하여,
중요한 정보를 그대로 유지하거나 수정할 수 있습니다. - 게이트 메커니즘:
LSTM은 셀 상태에 정보를 추가하거나 제거할 때 다음과 같은 게이트를 사용합니다.- 입력 게이트(Input Gate):
새로운 입력 정보를 얼마나 반영할지 결정합니다. - 망각 게이트(Forget Gate):
이전 셀 상태의 어떤 정보를 잊어버릴지를 결정합니다. - 출력 게이트(Output Gate):
최종적으로 출력할 정보를 선택합니다.
- 입력 게이트(Input Gate):
- 장기 의존성 해결:
이러한 구조 덕분에 LSTM은 RNN의 단점을 극복하고,
긴 시퀀스에서도 중요한 정보를 효과적으로 학습할 수 있습니다.
3. 데이터 준비 및 전처리
다음은 10년(120개월) 동안의 월별 평균 기온 데이터를 시뮬레이션하고,
LSTM 모델 입력에 맞게 전처리하는 과정입니다.
import numpy as np
import torch
import matplotlib.pyplot as plt
# 재현성을 위한 시드 설정
np.random.seed(42)
# 120개월(10년) 동안의 월별 데이터 생성
months = np.arange(120)
seasonal = 10 * np.sin(2 * np.pi * months / 12) # 계절 변동: 주기 12개월, 진폭 10
trend = 0.05 * months # 장기적 상승 추세: 매달 0.05씩 증가
noise = np.random.normal(0, 2, size=months.shape) # 노이즈: 표준편차 2인 정규분포 난수
temperature = 20 + seasonal + trend + noise # 기준 기온 20℃에 계절, 추세, 노이즈 합산
# 데이터 시각화
plt.figure(figsize=(10,4))
plt.plot(months, temperature, label='실제 기온')
plt.xlabel('월 (월수)')
plt.ylabel('기온 (℃)')
plt.title('월별 평균 기온 시뮬레이션')
plt.legend()
plt.grid(True)
plt.savefig('monthly_temperature.png', dpi=300)
plt.show()
그 다음과정으로는 슬라이딩 윈도우 방식을 통해 입력 시퀀스와 타겟 값을 구성하고,
LSTM 모델이 요구하는 (batch, sequence, features) 형태로 전처리합니다.
def create_dataset(data, window_size):
X, Y = [], []
for i in range(len(data) - window_size):
X.append(data[i:i+window_size])
Y.append(data[i+window_size])
return np.array(X), np.array(Y)
window_size = 12
X_data, Y_data = create_dataset(temperature, window_size)
print("입력 데이터 크기:", X_data.shape) # (샘플 수, 12)
print("타겟 데이터 크기:", Y_data.shape) # (샘플 수,)
# 학습/테스트 데이터 분할 (80% 학습, 20% 테스트)
train_size = int(0.8 * len(X_data))
X_train, Y_train = X_data[:train_size], Y_data[:train_size]
X_test, Y_test = X_data[train_size:], Y_data[train_size:]
# LSTM 입력 형식: (batch, sequence, features)
X_train_tensor = torch.FloatTensor(X_train).unsqueeze(-1) # feature 차원 추가
Y_train_tensor = torch.FloatTensor(Y_train).view(-1, 1)
X_test_tensor = torch.FloatTensor(X_test).unsqueeze(-1)
Y_test_tensor = torch.FloatTensor(Y_test).view(-1, 1)
4. LSTM 모델 구현
이제 LSTM을 활용한 회귀 모델을 PyTorch로 구현합니다.
import torch.nn as nn
class LSTMTemperaturePredictor(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMTemperaturePredictor, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# LSTM 레이어 정의 (batch_first=True)
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
# 마지막 시퀀스의 출력을 이용한 Fully Connected 레이어
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 초기 은닉 상태와 셀 상태 (num_layers, batch, hidden_size)
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
# LSTM 통과 (out: [batch, sequence, hidden_size])
out, _ = self.lstm(x, (h0, c0))
# 마지막 시퀀스 단계의 출력만 사용
out = self.fc(out[:, -1, :])
return out
input_size = 1 # feature dimension
hidden_size = 64
num_layers = 2
output_size = 1
model_lstm = LSTMTemperaturePredictor(input_size, hidden_size, num_layers, output_size)
print(model_lstm)5. 모델 학습 및 평가
LSTM 모델을 학습시키기 위해 MSE 손실 함수와 Adam 최적화 알고리즘을 사용합니다.
import torch.optim as optim
criterion = nn.MSELoss()
optimizer = optim.Adam(model_lstm.parameters(), lr=0.01)
num_epochs = 300
for epoch in range(num_epochs):
model_lstm.train()
optimizer.zero_grad()
outputs = model_lstm(X_train_tensor)
loss = criterion(outputs, Y_train_tensor)
loss.backward()
optimizer.step()
if (epoch+1) % 50 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')학습이 완료되면, 테스트 데이터를 이용하여 모델 성능을 평가합니다.
model_lstm.eval()
with torch.no_grad():
test_pred = model_lstm(X_test_tensor)
test_loss = criterion(test_pred, Y_test_tensor)
print(f'Test Loss: {test_loss.item():.4f}')예측 결과를 시각화합니다.
plt.figure(figsize=(10,4))
# 테스트 데이터에 해당하는 월 번호 (학습 데이터 이후의 월수)
test_months = np.arange(train_size + window_size, 120)
plt.plot(test_months, Y_test, label='실제 기온')
plt.plot(test_months, test_pred.numpy(), label='예측 기온', linestyle='--')
plt.xlabel('월 (월수)')
plt.ylabel('기온 (℃)')
plt.title('LSTM을 활용한 기온 예측 결과')
plt.legend()
plt.grid(True)
plt.savefig('lstm_temperature_prediction.png', dpi=300)
plt.show()6. 결과 분석 및 활용 방안
이번 예제에서는 LSTM 모델을 통해 과거 1년 간의 기온 데이터를 기반으로 다음 달의 기온을 예측하였습니다.
예측 결과와 실제 기온의 차이를 통해 모델의 성능을 평가할 수 있었으며,
LSTM의 장기 의존성 처리 능력을 확인할 수 있었습니다.
활용 방안:
- 장기 기후 변화 분석:
월별, 연도별 기온, 강수량, 대기오염 농도 등의 시계열 데이터를 활용해 장기 추세 및 이상 기후 이벤트를 탐지할 수 있습니다. - 지역별 기후 비교:
여러 지역의 데이터를 수집하여, LSTM 모델을 통해 지역별 기후 특성을 비교 분석할 수 있습니다. - 복합 변수 예측:
온도뿐만 아니라 습도, 강수량, 대기오염 등 다변량 데이터를 결합하여 복합 기후 모델을 구축하고,
기후 변화에 따른 다양한 시나리오를 예측할 수 있습니다.
연구자가 실제 측정된 환경·기후 데이터를 전처리하고,
LSTM 외에도 CNN, Transformer 등 다양한 모델로 확장하여 활용할 수 있습니다.
7. 결론
이번 포스팅에서는 이전 포스팅에서 다루지 않았던 순환 신경망과 LSTM의 새로운 개념을 먼저 소개한 후,
LSTM을 활용한 기후 시계열 예측 예제를 통해 실제 데이터를 분석하는 방법을 자세히 알아보았습니다.
새로운 개념의 이해를 바탕으로 LSTM 모델을 구현하고, 학습 및 평가 과정을 거쳐
환경·기후 데이터 분석에 적용할 수 있는 실질적인 방안을 제시하였습니다.
딥러닝은 기초 이론을 탄탄히 다진 후 다양한 응용 사례에 맞춰 모델을 설계하고 최적화하는 과정이 매우 중요합니다.
앞으로도 본 포스팅의 내용과 예제 코드가 여러분의 연구와 실무에 큰 도움이 되길 바라며,
지속적인 연구와 공유를 통해 더 나은 성과를 이루시길 기원합니다.
추후에는 Transformer, Attention 기반 모델 등 최신 시계열 분석 기법도 함께 다루도록 하겠습니다.